
「データが見つからなくて…この紙面データから文字起ししてくれない?」
なんて少し残念な“文字起し依頼”を経験されたことはございますか?
紙面を画像として取り込まれたPDFから文字起しなんていうのもそうです。
少量なら問題なくても、それが膨大な量となれば話は別です。
とても疲れる単純作業は心身共によろしくないですよね。
今回は、そんな苦痛なタイピング作業から少し解放される方法についてご紹介します。
Googleドキュメントを使う
Googleアカウントがあれば、どなたでも使えます。(もちろん無料)
画像データをこのドキュメントで読み込めば、テキストデータ(文字化)として抽出できます。
テキスト抽出フロー
普段よく使われている、
紙面をコピー機などのスキャナー機能を使って画像取り込みされたPDFデータ
これを想定して、やってみます。
厚生労働省のHPから「新型コロナウイルスを防ぐには」なるPDFを見つけましたのでこれを例とします。(せっかくなので役立つ内容を…)
※元のPDFはテキストデータで、そのままテキスト抽出できてしまいますから、いったん画像化しました。

①Googleドライブを開けて、画像をドラッグ&ドロップ
すぐにアップロードされてファイルが表示されます。
②このファイルを右クリックして「アプリで開く」→「Googleドキュメント」を選択
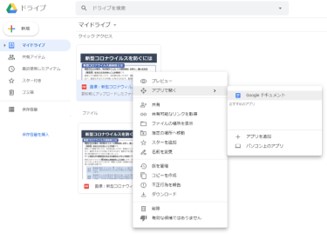
③処理時間をおいてテキストが表示される
このファイルは処理に5秒ほどかかりました。
こんな感じ↓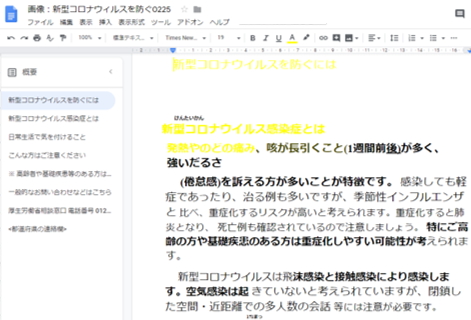
左窓にはドキュメントさんが考えた見出しが作られて、本文(テキスト)が作られました。
枠の認識はされずに、文字と思われる画像を拾ってテキスト化してくれています。
あとはこれをコピーして利用できますね。
色認識や改行のセンスがちょっと…と疑問もありますが、延々と手打ちさせられるよりは随分お役に立ってくれると思います。
受け取った見積書の内訳を、データ化したい!なんて場合にも活躍します。
他社から提示される見積書は、編集を防ぐために画像データで提出されることが多いですよね。「元データ欲しい」なんて言うと嫌がられます。
とはいえ、取引データとしては詳細にデータ管理したいのも事実なので、本機能を活用すれば情報の取り込みがラクにできますね。
原本はなるべく鮮明な状態
Googleドキュメントさんは形の崩れた文字の認識が苦手です。
手書きを取込んで試してみましたが不可でした。
私の字が下手なので無視されたのかも(笑)
明朝体やゴシック体を手書きできる方は、もしかすると認識されるかもしれません。

